A Gentle Introduction to Biometry.
Biometry is a very wide field - recognition methods, efficiency, security, privacy, ... There are so many sub-topics which are all important to consider when implementing a biometric system. Here, we will try to cover most of these topics, to give you starting clues to understand what is at stakes.
Introduction
We mostly know biometric from the user side: put your finger on your phone, show your face, place your hand above the sensor, etc. It seems super easy. However, the system needs to be full proof. A password works all the time, because you input exactly the same string each time you authenticate. For biometry, it relies on a sensor, and the way your attribute is captured depends on many factors. Additionally, your biometric trait may change over time, because of natural renewal, aging or disease. Therefore, biometric relies on very specific algorithms enabling us to extract a reliable bioprint and compare it accurately with a reference.
Table of Content
- Introduction
- Authentication categories
- Biometric requirements
- Categories
- Biometric bestiary
- Evaluation metrics
- Security
- Conclusion
- Source
Note: This is a very long article. Look at the ToC to study one topic after another.
Authentication Types
There are three ways to prove your identity, or to prove to be the owner of something:
- what you know
- what you have
- what you are
Knowledge
Within this category, there are passwords, PINs, a confidential information that you are the only one to know. This is “lightweight”, always available. That is also easy to share with a friend if necessary, and you can change it later to revoke the shared access.
However, it has its drawbacks:
- Memory-related issues: when you are drunk or tired, remembering the password, or typing it is difficult. Similarly, if you are affected by a mental disease, aging, or an accident, your memory can fade away,
- More importantly: password reuse 1. Today, we need passwords everywhere, for all websites. The best practice is to never reuse a password. Otherwise, if one service is compromised, then all the services where the same password is used are compromised too.
Today, there are many passwords’ policies2,3, trying to prevent weak passwords:
- Add a number,
- At least one upper- and lower-case character,
- At least one special character,
- And at least
xcharacters4.
Because such kind of password becomes so difficult to remember, it does not help to improve password diversity 5. One way to avoid password reuse is to use a key manager, like Keepass. However, without it, you cannot unlock your accounts.
Assets
The second way to claim your identity is to have a physical or a digital objects. This can be a key (for a door), a Yubikey, a RFID tag, a RSA private key, or a password stored in a key-manager (Keepass for instance).
The problem is availability, loss, destruction, corruption, and theft. You need to protect the item, carry it with you. Hopefully, you can often make a copy, stored in a secure place.
Being
The last one is what you are, your traits and characteristics: this is where biometry stands. The main advantage is that you always have it with you, and you do not need to remember anything.
While it seems super-cool, there are many drawbacks, which depend on the biometric characteristic considered.
- Some biometric traits can be copied, or mimicked. If someone can copy it, it might be available to the attacker forever.
- Some biometric traits change over time and are affected by diseases. At some point, you might not be recognized anymore by the system. You need to update your bioprint periodically.
- Some traits are not discriminative enough; you could be taken for someone else.
These are the main drawbacks, but there are others (as well as password and knowledge).
Summary Table
| Authentification type | Advantages | Disadvantages | Examples |
|---|---|---|---|
| Knowledge | Available everywhere | Forgotten, shoulder surfing | Pin, password |
| Asset | Cheap | Lost and theft | Smart card |
| Biometrics | Unique, Unforgettable | Cost, invasive | Fingerprints, Voice, Keystroke |
Biometric Requirements
There are plenty of possible biometric features: fingerprint, palm shape, palm vein, fingervein, gait, taping speed, iris, face, face geometry …
However, they are not all equivalent, some are better than others when considering specific criteria. The main evaluation is accuracy: how distinctive the trait is, but it is not the single point to consider.
There are several articles pointing out what needs to be considered in a biometric system:
- Uniqueness: Is it distinctive across users? Height is not unique, but iris pattern is.
- Permanence : Does it change over time? Voice changes a lot between the morning and the end of the day.
- Universality: Does every user have it?
- Collectability: Can it be measured quantitatively?
- Acceptability: Is it acceptable to the users? Face recognition is not welcome in Europe
- Performance: Does it meet error rate, throughput, etc.?
- Vulnerability : Can it be easily spoofed or obfuscated? This is easy to take a photo of your face, however it is difficult to reproduce your vein patterns.
- Integration : Can it be embedded in the application?
- Circumvention Easy to use a substitute, easy to foo the system?
Almost no system is optimal, none is perfect. For instance, fingerprints “seem” available for everyone, up to people with a missing hand or fingers. However, if your skin is too dry or too wet, or dirty, it is impossible to be recognized by the system. Many of the systems are admissible: they do work for most people most of the time. An alternative should be provided for people who cannot use the system.
For permanence, this needs to be evaluated over the long term. However, gait evolves due to aging and disease. In that category, we need to consider the possibility for voluntary modification (plastic surgery), to evade service.
For the last metrics, this is system related metric, which is more about project feasibility. If your biometric system is accurate but requires an expensive capturing device, 10 minutes of processing, forget about it!
Biometric Systems
Before looking at biometric algorithms, categories, and peculiarities, let’s talk about the general system.
Basic Infrastructure
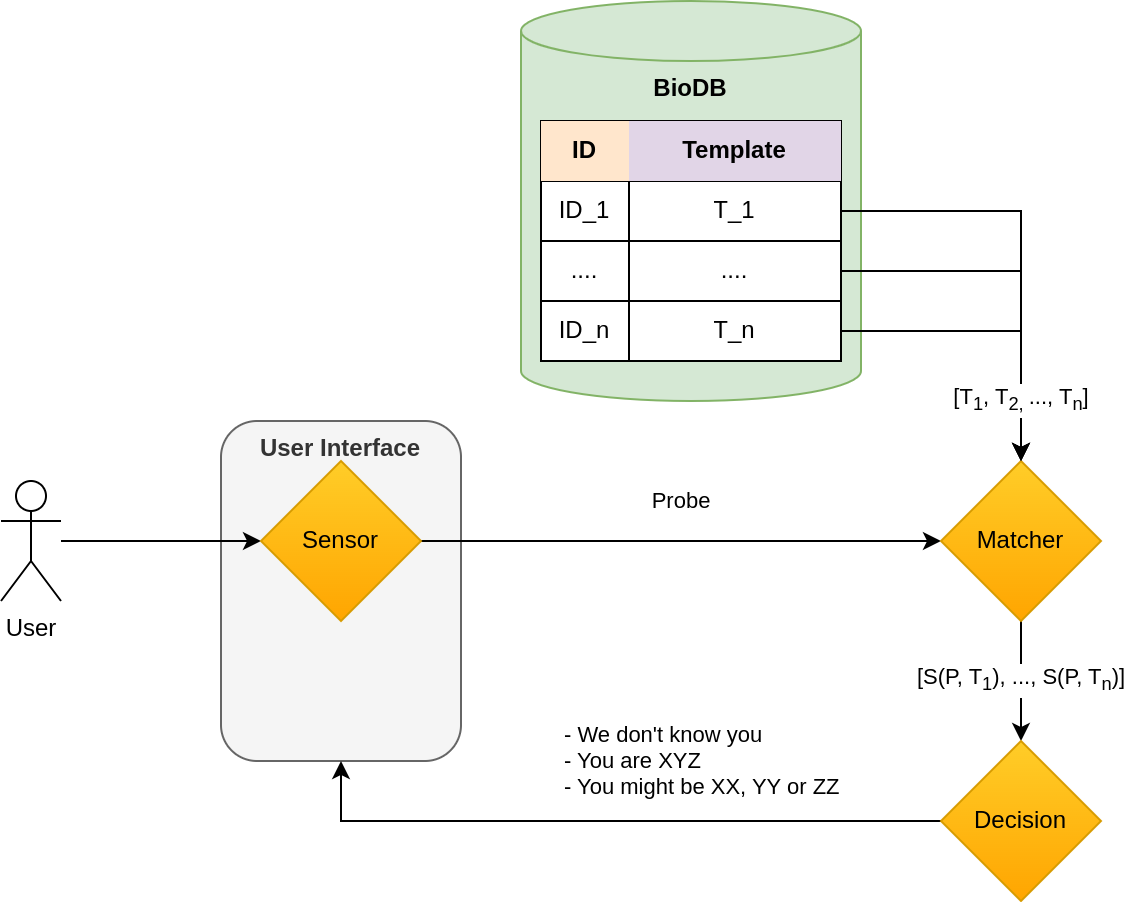
For a biometric system to work, you need at least four physical elements:
- a sensor: It collects biometric templates/patterns,
- a feature extractor: It transforms the raw data from the sensor into a pattern,
- a database: As the name suggests, this is where templates are stored,
- a matcher: This element compares one template (a stored element) to one probe (a freshly collected element) and outputs a score.
- a decision system: This element works with the matcher. It implements decision strategies.
Depending on the use case and security requirements, these elements are placed differently.
For instance, the sensor could be on the user device (a smartphone), or on the service provider side. The same for the feature extractor: near the sensor, to send something lightweight to the backend , or in the backend, so the technology is protected. The user pattern could be stored:
- on its own device (so if there is any breach on the central system, templates are not disclosed),
- on the device with the sensor (there is no distant database)
- on a remote database
The matcher can be anywhere else: on the user device, on the sensor device, near the remote database, or on another location.
Comparison Modes
A biometric system has two modes:
- Verification: You claim you are M/Mrs
X, the system checks the claim. This is a1:1comparison. The reference is compared to the freshly captured probe. - Identification: No claim is made. The system tries to find you in the database. This is a
1:ncomparison, as you compare \(1\) probe to the \(n\) stored in the database.
Verification
In verification, the matcher outputs a similarity score \(S\). If \(S(\text{Probe}, \text{Template}) > thr\), then the claim is accepted, otherwise, it is rejected by the decision system.

Identification
In identification, the matcher compares all \(n\) templates available in the database to the current probes. Therefore, we get \(n\) scores. Here, there are multiple options:
- Return the best one,
- Return the top \(k\),
- Return all elements where \(S(T_i, \text{Probe}) > thr\)
- Keep all top \(k\) elements and returns only those where \(S(T_i, \text{Probe}) > thr\)
- …
There are many decision strategies. This previous list are the main possible choices if we only consider biometry as a decision factor. You can add other information. For instance, if you have access to the user address (where he lives), you can compare the location of the sensor to this address. If the sensor is located in Paris while the user lives in England, this information will decrease the likelihood of this user being the one in front of the sensor.
Which one is the Best ?
Verification and Identification do not answer the same question. Nevertheless, verification is easier than identification. Accuracy when performing identification depends on the threshold and the database size. This is very intuitive: if you are given a trombinoscope with 10 people here, it is much easier to find who is who or if the person is not in the book than when there are \(1,000\) people in
Biometric Categories
In the previous section, we described what are the elements of a biometric system. Here, we will describe the main categories:
- active VS passive
- static, periodic, or continuous
Active VS Passive
In active systems, the user must perform an action:
- Put the finger/hand over the sensor,
- Keep the eyes wide open,
- Say a particular sentence.
In passive biometric systems, the user is never asked to do any particular action.
The system will collect clues during a certain period and emit a decision.
For instance:
- Face recognition
- Gait analysis
- Typing on a keyboard or signing a document
Examples Falling in Both Categories
A biometric trait can be used for active as well as for passive systems. It depends on how data is collected.
Face recognition can be in both category:
active: when you want to unlock your phone, you need to show your face to your camera,passive: you walk in a shop, cameras take some pictures of you, and when you pay, the system knows who you are.
Voice recognition also falls in these two categories:
active: keyword based: the user is asked to say a particular sentence.passive: free speech analysis: The microphone records a conversation, and decides when high confidence
Summary
- active systems send you a challenge that you need to solve know, and capture at the same time your consent,
- passive systems try to be as invisible as possible to avoid interrupting you. As the user is “unaware” that the system is running, consent is not checked here, and must be obtained at enrollment time.
Static - Periodic - Continuous
At first glance, periodic VS continuous authentication is equivalent to active VS passive. However, it is not. Here, the question is when do you make the decision? while for active/passive, it is related to how do you collect clues – with or without asking?. We can make a distinction between decision strategies:
- In static evaluation, once a proof of you have been obtained, then you can use the service (open a door, log in on your computer, …)
- In periodic evaluation, this is similar to static, but you repeat the process every x minutes/hours
This evaluation can be done with active or passive features:
- active: you are asked to put your finger, show your face,
- passive: the system will analyse for a few seconds / minutes your behavior / characteristic, and then take a decision.
For continuous, this is different: clues will be collected continuously, or at least every x seconds/minutes, and then, this will be used to update a score. you never tell the user “OK, you’re good”. You only block operations if the user asks for something critical but we are not sure. In this scenario, it prevents prompting the user when it is not necessary.
Biometric Bestiary
At some point, we need to list a few biometric attributes, and give an idea of which features are considered.
Here, we grouped biometric technics by kind:
And a last paragraph for the miscs, which have been studied, but are impractical in real life.
We do not list their accuracy: over time, systems are likely to evolve in a positive way. Maybe someone tomorrow will find a very accurate algorithm for one or the other modality.
Physiological / Static
- DNA
- Iris
- Retina
- Fingerprints
- Palm print
- Hand geometry
- Vein: Palmvein, fingervein, …
- Face recognition: appearance, geometry, and thermal-based
DNA
A human has \(2 \times 23\) chromosomes (one from each parent), which are identical over all the cells (up to some replication errors).
Each chromosome is a sequence of nucleotides, where there are 4 choices for each slot: A, T, G or C.
In total, there are \(3 \times 10^9\) slots for human DNA.
Humans are similar in their general structure, but they are not identical. DNA reflects that: there are common sequences that are highly functional where one single change would cause a disaster, and there are locations which accept variations. So in reality, there is much less than $4^{10^9}$ human possibilities.
When performing a DNA test, not all the DNA is scanned. Only interesting parts, which are called “SNP”, for Single Nucleotide Polymorphism. You can take a look at SNPEDIA, which lists SNP, which protein they code, what change leads to what, and other info.
Replication errors are very low; therefore this information is highly stable and accurate. However, it cannot be used on a day-to-day authentication basis, because analysis takes a lot of time and is costly for such a kind of application (For 23andMe, it cost 230$ today. 5 years ago, it was 100$, this is business!).
Iris 6
Iris does not really change over time, and are highly discriminative, making this biometric modality a very good candidate. The only problem is user cooperation, as the eyes must be wide open in front of the sensor.
This is thanks to this technic that the famous Pakistanese woman was recognized, years and years after the initial photograph.

Steve McCurry/National Geographic Society, via AFP
It is good to highlight that eyes color does not matter! Brown eyes seem dark because they absorb more light than light colors. However, with proper light, all the wonderful patterns are revealed.
How features are Extracted ? 7
- Find the Iris region
- Find the Retina region
- Flatten / unroll the iris part
- Normalization
- Extract phase using Gabor Wavelet
- Perform code binarization / thresholding

Because we obtained binary codes, two iris codes are compared by measuring their Hamming distance, which is basically the number of different bits.
Retina 8, 9, 10
In the “vein recognition biometry” systems, there are biometric systems exploiting vein retina pattern.
The processing is similar to palmvein and fingervein processing, so check the following paragraphs.

Image from Robust retina-based person authentication using the sparse classifier 8.
Fingerprints 11
A fingerprint is made of lines (called ridges), which form patterns (loops, whorl, or arch), and which cross or end. These ending/merging locations are called minutiae. Analysis can be done looking at ridges patterns or minutiae patterns or both.
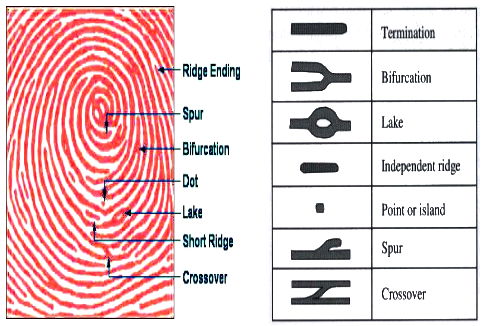
Minutiae illustration, Image from Multimodal Biometric Authentication System - MBAS.12
How to ?13
- Segmentation: identify fingerprint area out of the background
- Process the image to enhance contrast to get ridge lines visible. Use Gabor filter for instance.
- Identify minutiae
There are three main matching methods:
- Correlation based: compare two images (without using minutiae, but with image enhancing)
- Minutiae based: compare minutiae location. The algorithm will search for the minimal distance between minutiae.
- Ridge based: This is similar to iris code, where around each singular pattern (a loop for instance), you extract a binary code from the neighborhood area.
Palm Print 14, 15
This method is similar to fingerprint recognition systems. But instead of your finger image, it looks at the main lines on your palm. Normally, fingers are not considered.

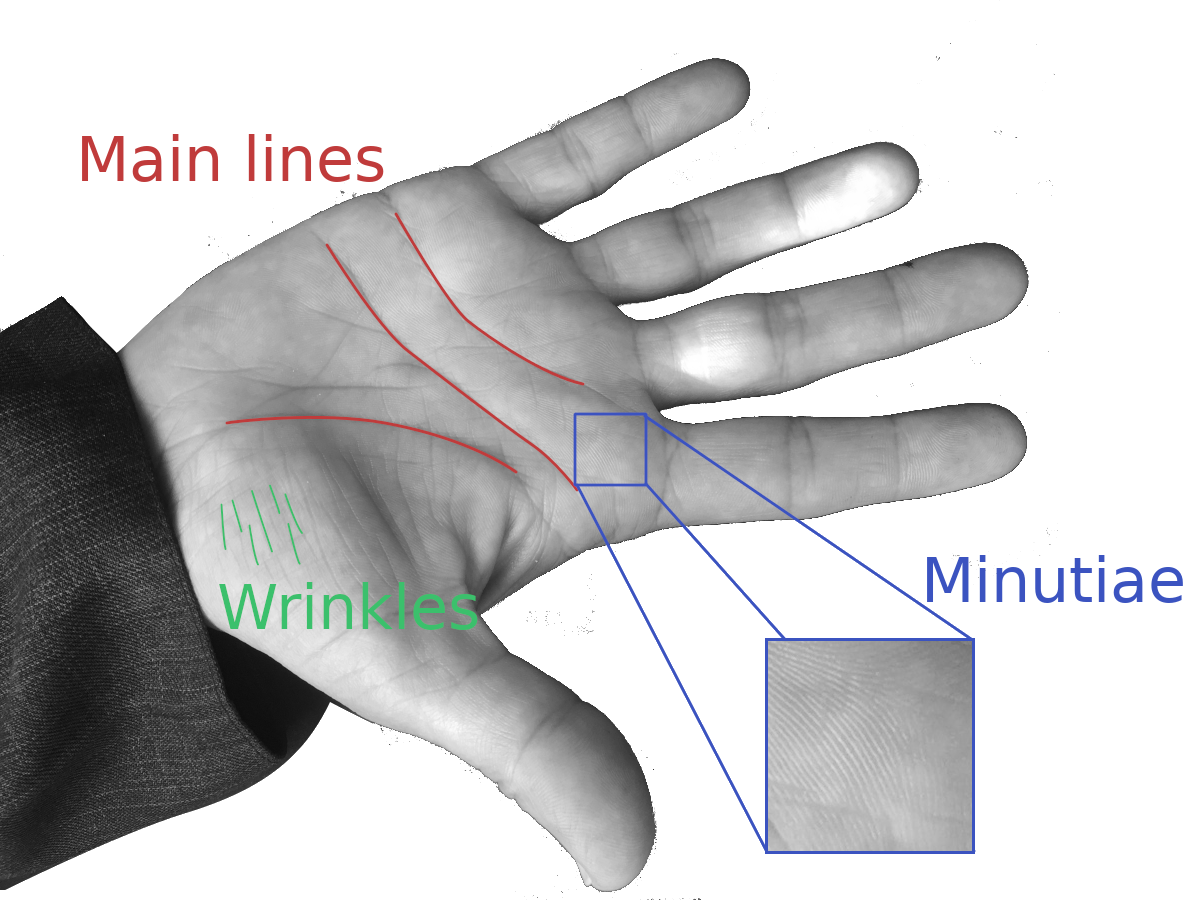
Image from BMPD dataset (Kaggle)
The processing is similar as for fingerprints:
- First, a preprocessing to enhance contrast
- Palm Extraction
- Finally, feature extraction.
Hand Geometry 16
AS the name suggests, this method looks at the different length and location of your fingers:
- The ratio between the palms and the fingers
- The shape of your finger
- Phalanx length
- Thumb location
Compared to palmprint, these features can be obtained without a high-quality camera. Nevertheless, because there are much less features than for palm print, this is also less accurate.
However, this can serve as a second factor for biometry.
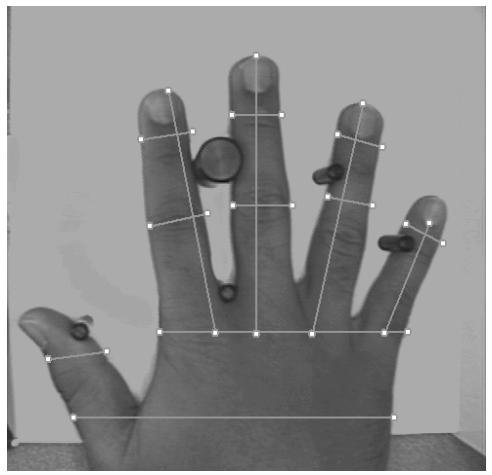
Image from “A Prototype Hand Geometry-based Verification System” 16
Veins Pattern Analysis 17,18, 19
Here, you have finger veins, palm veins, and retina veins which are processed by the same kind of device and algorithm.
The advantage of veins is that producing a copy is difficult. This technology relies on blood absorption of light by de-oxygenated blood. First, having a good IR sensor is expensive. Next, gathering enough accurate samples from a non-cooperative human is a challenge. And last, making a copy able to absorb to the same wavelength and fool the liveness system is hard to create.
The processing is the following
- The sensor capture an IR image, which is a black and white image (the sensor is calibrated for one specific wavelength, not to capture the full temperature spectrum)
- Some pre-processing is done to remove noise and enhance contrast
- Line detection (veins appear black)
- Find the crossing points (between the lines)

Image adapted from “ZKTECO College - Fundamental of Finger Vein Recognition”18
Compared to fingerprints, you have much less crossing points (which are the analog to the minutiae). So, you need to rely on both vein lines (which are less smooth than ridge lines) and crossing points. Crossing points are often helpful to first align two templates, and then compare their lines.
Face Recognition
In this category, there are many subtopics:
- Face geometry
- Face thermography
- Appearance-based facial recognition (despite the name, this is the most common)
Face recognition is a large research topic because of the ubiquity of capturing devices. It can serve for active as well as for passive authentication (unfortunately, mass surveillance is one of the top use-case).
Appearance-based Facial Recognition 20,21,22,23
This technic is one of the most common today, to unlock a smartphone or PC, for border controler with your image stored on your passport, …
The main problems with this biometry are 20:
- Physical changes: Aging, make-up, clothes, facial expression, glasses, scars, spots…
- Acquisition geometry: Scale, rotation, location in the plane
- Image recording: Light variation, sensor pre-processing, color encoding, compression.
At the start, face patterns were extracted using PCA20. All these systems rely on convolutional neural networks 21,22,23 which are very good at finding local discriminative patterns despite their high training cost.
Face Geometry 24, 25, 26, 27
As for hand geometry, face geometry relies on the location of face elements (eyes, nose, ear, …), and the distance between them. Compared to appearance-based face recognition system, it is less subject to errors, as the considered elements do not move over time. However, due to the small number of features, false positive can exist over large databases.
The usual processing is the following:
- Detect the face
- Segmentation
- Image enhancement
- Landmarks detection
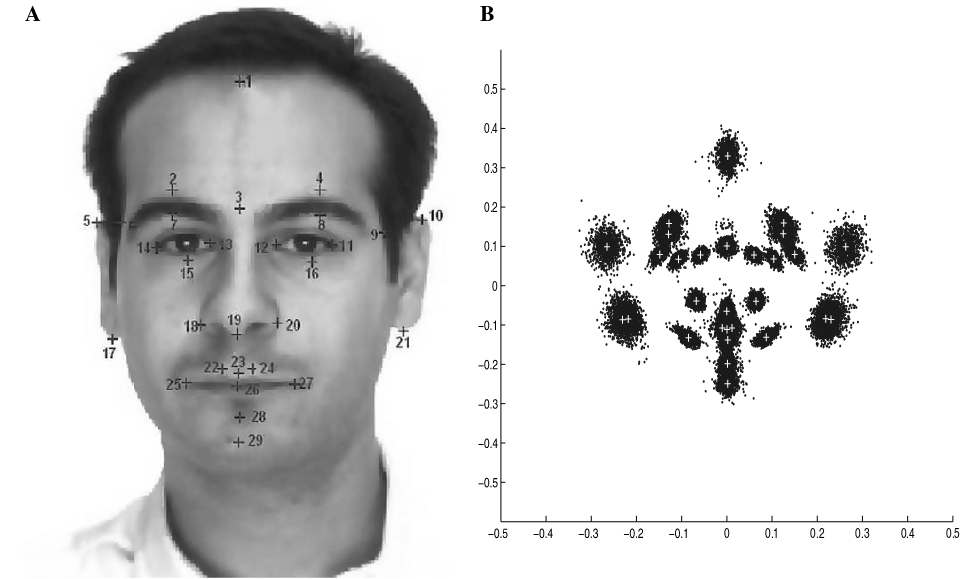
Image from “How effective are landmarks and their geometry for face recognition?” 25. Part A shows 29 landmarks over one image, Part B shows the landmarks distribution over 994 different faces.
From these landmarks, we can compute angles and distances, which enable comparing two templates together.
With advanced methods and several captures, it is possible to create accurate 3D models of the face.
Face thermography 28
Face thermography differs from vein analysis on two points:
- Sensors are different: they are calibrated over a large IR spectrum to get temperature
- The method does not rely on veins location.
There are few works on the topic. In 28, the processing is described as:
- Image registration: kind of normalization
- Thermal signature extraction
- Face Segmentation
- Noise removal
- Image morphology
- Skeletonization: finding lines to describe the face
- Pattern generation
Because it relies on face temperature, liveness is always ensured: fake faces (photo, screen, 3D models) would not work.
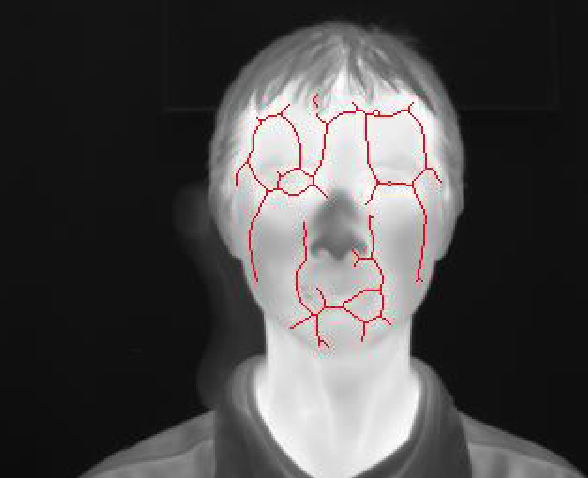
Image from Ana M. Guzman Tamayo, (2011), “Thermal Imaging As A Biometrics Approach To Facial Signature Authentication”.28
However, this method is sensitive to many factors 29:
- Gender (on average, men have a higher temperature than women)
- Exercise (if you just climb stairs or if you were sitting)
- Health condition (if you are sick)
- Weight (change in fat distribution impact energy consumption)
- Room temperature
Behavioral
Behavioral biometrics are factors which need some time to be recorded. This is not one picture; this is a time series.
Voice 30, 31, 32, 33
Voice biometrics is a very active research area, as face recognition is.
There are many factors impacting recognition:
- Microphone and compression quality
- Health condition (disease, sports, temperature)
- Aging
- Ambiant noise
All these factors make recognition challenging.
How Processing is Done
Most algorithms are unable to process raw audio signal. The first pre-processing step converts audio waves using a time-Frequency transform, like FFT (Fast Fourrier Transform) or Wavelet transform.
The basic pipeline is the following:
- Perform FFT/ Wavelet decomposition (you obtain a Lofargram)
- Compute MFCC (Mel Frequency Cepstral Coefficients) (compress frequencies into bands)
- User representation: Gaussian Mixture Model 33 (old fashioned), or Deep-learning models 30.

Unprocessed Audio Waves

Corresponding Lofargram: when there is voice, you can see non-straight lines.
About MFCC, if you look at frequencies for the tone “La/D”, the main reference frequency is 440Hz.
If you look at the frequency values of the different “La/D”, you get:
What you see is that the frequencies for a “La” are \((55)^n\), where \(n\) is an integer. The scale is not linear at all as the size of the interval doubles each time you increase \(n\) by \(1\). MFCC are here to correct that, to get the same number of features per interval. You can find a good introduction on how they are calculated here 31
Gait Analysis 34, 35, 36, 37, 38
Gait analysis studies the way you walk, how your arms bounce, etc. Compared to other biometry, data can be collected using different kinds of sensors:
- Camera
- Smartwatch / Smartphone
Therefore, each has is set of dedicated algorithms, so there is no general processing procedure. Smartwatch and smartphone are very similar. The only difference is the location, where a smartphone is in a pocket or in a handbag, while a smartmatch is attached to the wrist.
In the case of gait analysis using a camera, first, the moving user must be isolated from the background. We get the user’s silhouette. We need to extract features of it (knees, hip, feet location), and study the time series obtained.

Image from “Biometric Authorization System Using Gait Biometry”.34
For smartwatch / smartphone gait analysis, they both rely on accelerometer. There are several pre-processing steps:
- Outliers removal, where abnormal peaks are discarded
- Resampling: even if sensors should return a 100/200Hz signal, some elements are missing depending on the sensor and OS. Therefore, the missing points should be recovered using resampling.
- Noise removal: sensors are subject to electromagnetic noise, that should be removed for a cleaner analysis.
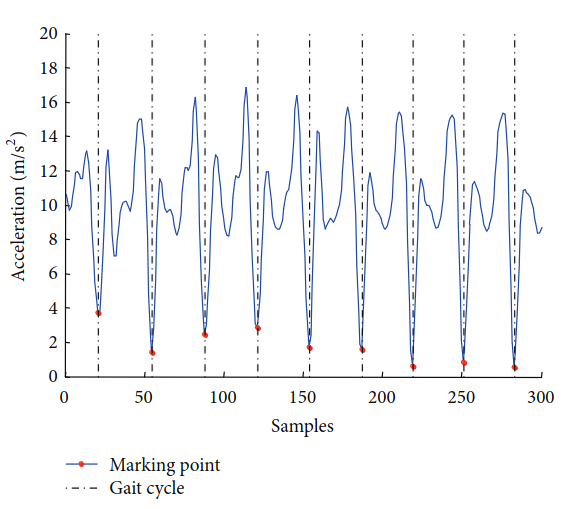
Image from “Secure and Privacy Enhanced Gait Authentication on Smart Phone” 37.
Next stands the so called “feature extraction phase”, where you can use statistical features (mean, std, skewness, …), force (or sum of acceleration), angles, and cycles related info (gait cycles length, waveform length, FFT coefficients, …) 37. This analysis is done on a segment of several seconds. In some papers35,36, they recommend 15 seconds of active walking.
Keystroke 39, 40, 41
We all place our hands differently on a keyboard, use some fingers to press specific keys, and our typing speed depends mostly of our job. By analyzing the speed between two keystrokes, we can guess who is who. Another factor is the press time, i.e., the duration of a key-pressed (in contrast to the flight time, which is the time to move from one key to another). These frequencies help to create a user representation, to compare to a new trace.
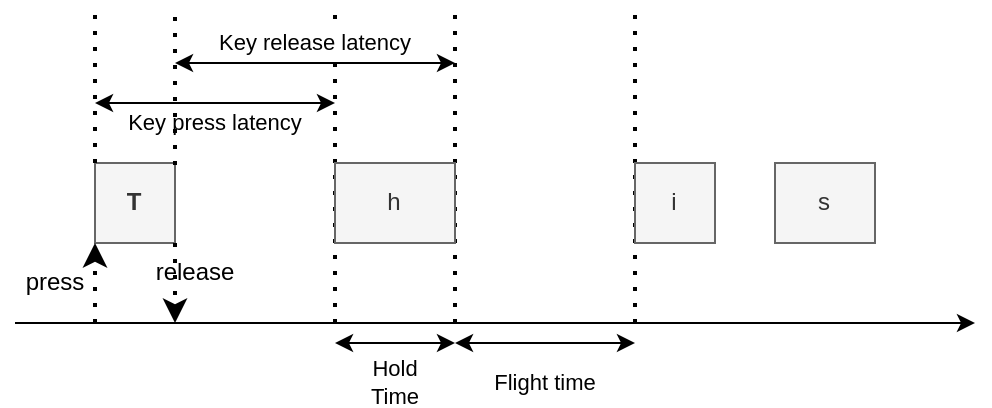
Here, as for voice biometrics, device counts: the way you type on a mechanical VS a membrane keyboard, the layout, the size (13 inch or 15 inch), all these factors impact the typing speed. Therefore, it can be used to authenticate the user on his own computer, or over a similar computer, but the typing pattern cannot be translated to another one.
Keystroke can be generalized to smartphone, where you can additionally consider key pressure.
Signature 42,43,44
We can identify someone based on the way the signature is drawn. You have two ways to perform the analysis:
- static (compare two images of a signature)
- dynamic, using the pen location, speed, etc.
While a fresh static signature can be considered as behavioral biometrics, it is very easy to spoof it and inject a previous one in the system. Therefore, we only consider dynamic approaches as behavioral biometrics.
There are two main ways to process dynamic signatures:
- Time series based
- Feature based

Image from “An On-Line Signature Verification System Based on Fusion of Local and Global Information” 43.
Time series-based
When we draw a signature, there are several elements that are recorded:
- the location \((x, y)\)
- the pressure (optionally)
From those informations, we can measure speed and acceleration.
Time series are (often) compared using DTW (Dynamic Time Warping) 44,42, which searches for the minimal distance between two time series.
Features-based
Instead of comparing time series, which requires accurate normalization, one could look at features. We can list a few:
- The total signature duration
- The number of extrema points
- The number of pen-up
- Statistical features (mean, var, …)
These features can be compared using machine learning algorithms or traditional statistical tools. For instance, using the Mahalanobis distance 44, which pays attention to scaling and correlation between variables.
Miscs
These last technics are not used commercially:
- or sensors are too invasive
- or they are prototypes, experiments, but not much
We just mention them here, even if the literature is quite small.
ECG
Recognition of someone based on his/her heartbeat.
- Arteaga-Falconi, J. S., Al Osman, H., & El Saddik, A. (2016). ECG Authentication for Mobile Devices. IEEE Transactions on Instrumentation and Measurement, 65(3), 591–600. doi:10.1109/tim.2015.2503863
- Huang, Pei & Guo, Linke & Li, Ming & Fang, Yuguang. (2019). Practical Privacy-Preserving ECG-Based Authentication for IoT-Based Healthcare. IEEE Internet of Things Journal. PP. 1-1. 10.1109/JIOT.2019.2929087.
EEG
EEG (for Electroencephalogram) aims to identify someone based on the brainwaves. Usually, EEG experiments are conducted with several dozens of electrodes. However, in daily life, it is not possible to wear such a thing on your head. So, the idea is to infer something with very few electrodes.
- Marcel, Sébastien & Millan, Jose del R.. (2007). Person Authentication Using Brainwaves (EEG) and Maximum A Posteriori Model Adaptation. IEEE transactions on pattern analysis and machine intelligence. 29. 743-52. 10.1109/TPAMI.2007.1012.
- Bidgoly, A. J., Bidgoly, H. J., & Arezoumand, Z. (2020). A Survey on Methods and Challenges in EEG Based Authentication. Computers & Security, 101788.
- T. Nakamura, V. Goverdovsky and D. P. Mandic, “In-Ear EEG Biometrics for Feasible and Readily Collectable Real-World Person Authentication, in IEEE Transactions on Information Forensics and Security, vol. 13, no. 3, pp. 648-661, March 2018, doi: 10.1109/TIFS.2017.2763124.
- Mu, Zhendong & Hu, Jianfeng & Min, Jianliang. (2016). EEG-Based Person Authentication Using a Fuzzy Entropy-Related Approach with Two Electrodes. Entropy. 18. 432. 10.3390/e18120432.
- Riera, Alejandro & Soria-Frisch, Aureli & Caparrini, Marco & Grau, Carles & Ruffini, Giulio. (2007). Unobtrusive Biometric System Based on Electroencephalogram Analysis. EURASIP Journal on Advances in Signal Processing. 2008. 10.1155/2008/143728.
Ear Shape
As a human, we are used to identify someone based on the face: eyes, noise, mouth, … We face people, we do not look at them by their side.
Nevertheless, the ear is a distinctive sign. The main problem with this technic is hairs: many people have hairs covering their ears, making this method impractical without cooperation
Biometric Recognition Using 3D Ear Shape
Lips Shape
- Wright, Carrie & Stewart, Darryl. (2020). Understanding visual lip-based biometric authentication for mobile devices. EURASIP Journal on Information Security. 2020. 10.1186/s13635-020-0102-6.
- Isaac, Maycel & Bigun, Josef. (2007).Lip biometrics for digit recognition 4673. 360-365. 10.1007/978-3-540-74272-2_45.
Skin Reflectance
Heard about, no serious papers on the topic.
Odor
As dogs can search for humans based on their clothes, it might be possible to recognize people based on their corporal odor. This is more a prototype than a true biometric system.
-
Akinwale, Oyeleye & M., Fagbola & Babatunde, Ronke & Baale, Adebisi. (2013).An Exploratory Study Of Odor Biometrics Modality For Human Recognition
-
Karanassios, Assal (2022)Preliminary work on the Opinions on and Acceptance of Obscure Biometrics: Odor, Gait and Ear Shape, Usenix.
Evaluation Metrics
As discussed earlier, a biometric system works in two modes:
- Verification, or
1:1comparison - Identification, or
1:ncomparison
For each scenario, you have dedicated metrics.
The verification metrics are not equivalent to identification ones: they are only similar in their interpretation. You cannot compare one system doing verification to another doing identification. Identification systems should have diverse patterns to prevent false positive identification.
Verification
Verification is like a traditional classification problem with two classes where there are \(4\) possible outcomes:
| \(\hat{0}\) | \(\hat{1}\) | |
|---|---|---|
| \(0\) | TN | FP |
| \(1\) | FN | TP |
Rows represent truth, while columns prediction.
F = False, T = True, P=Positive, N=Negative
The two typical metrics to evaluate verification are FRR and FAR.
FRR: False Rejection Rate
The False Rejection Rate is the number of wrongly rejected transactions over the total of true claims. I.e, the number of times a true user claim has been rejected:
\[FRR = \frac{FN}{FN + TP} = \frac{\text{# Good user not recognized}}{\text{# Enrolled user trial}}\]FAR: False Acceptance Rate
The False Acceptance Rate is the number of wrongly accepted transactions over the total positive outcomes. I.e, the number of times a wrong user has been identified as User X:
Identification
In identification, there are two groups: enrolled people, and the rest. The more people are enrolled, the harder the task is as the confusion risk increases.
As discussed previously, for identification, the decision subsystem can return no element, 1 element or several elements. We will differentiate the cases where you have 0 or 1 element, versus the case where you expect a list of elements.
One Item
\(FNIR\): False Negative Identification Rate
For an enrolled user, there are three outcomes:
- Correctly recognized (TP)
- Recognized as someone else (?)
- Not found (FN)
The “recognized as someone else” is problematic. Depending on the situation, the outcome can be considered differently:
- It can be a false positive.
- It can be a false negative
- It can be in between.
If the biometric system controls door opening. If you are recognized as someone else within the same access group (i.e., you are recognized as someone with the same rights as you), then there is no impact. However, if you are recognized as someone with less privileges, then it is a problem for the user as he might have access denied. And if this is about your bank account, being recognized as someone else is a big issue and cannot be tolerated.
Depending on how we count and design the experiments, we can count it as a fale positive or a false negative. But most of the time, it will be counted as a false negative.
The False Negative Identification Rate is the analog of FRR. This is the number of time a user enrolled has not been recognized:
We can split this metric in two, to get the misrecognition rate, and the not-found rate:
\[FNIR_{\text{miss reco}} = \frac{?}{ TP + ? + FN}\] \[FNIR_{\text{not found}} = \frac{FN}{ TP + ? + FN}\]When you look at the FNIR, the formulation is the same as the FRR. However, the experimental protocol is different, and you do not compare the same thing:
- in verification, if you have \(n\) users enrolled, you perform only \(n\) trials (or more if you have many probes from one user)
- in identification, if you have \(n\) users enrolled, you perform \(n \times n\) comparison (but take only \(n\) decisions).
The name is here to avoid confusion between the scenario, nothing more.
\(FPIR\): False Positive Identification Rate
For someone not enrolled, there are two outcomes:
- Not found (TN)
- Recognized as someone (FP)
The False Positive Identification Rate is analog to the FAR: This is the rate at which someone not enrolled is recognized as someone:
Unsorted List - Fixed Size
If the decision system returns an unsorted list, there are two outcomes for the enrolled user:
- In the list (TP)
- Not in the list (FN)
There is no concept of “misrecognition”. The FNIR is computed as \(\frac{FN}{TP + FN}\), where the list size does not count.
For the FPIR, we expect the list to be of size \(0\).
Unsorted List - Variable Size
In the case where the size of the list changes, depending on the number of potential matches found, the two metrics can take this information into account:
- FNIR: the longer the list, the more weight is accorded to false positive (as if the user is not in the list, then a bunch of people were returned for nothing).
- FPIR: the longer the list, the more confident the system is about the person is enrolled. A greater penalty should be added in the case the user is not enrolled.
There is no standard formula to compute the metrics for this case. The formula needs to be designed case by case.
Sorted List
For security reasons, the decision subsystem must not return scores to the final user (this is to prevent template generation attack). However, sending an ordered list is fine.
In that case, we can compute the weighted score. There are several ways to do that, taking the rank into account.
Here, as for unsorted list, there is no standard formula. You can take a look at recommender system’s formulas, like NDCG for instance.
Calibration
We have one free parameter which is the decision threshold. We can decide to increase it (makes verification/identification more difficult), or to lower it. This change would impact the two metrics:
| threshold: | low | medium | high |
|---|---|---|---|
| FAR/FPIR | +++ | + | - - |
| FRR/FNIR | - - | + | +++ |
When you report the metric of your biometric system, you can say “My (FAR, FRR) is (X, Y)”.
However, if you are developing the technology to be used by someone else, it is much better to produce an (FAR, FRR) diagram.
This is a diagram where the x-axis represents the FAR and the y-axis the FRR.
There, you report (FAR, FRR) for different threshold values.
A very similar curve is the Detection Error Tradeoff curve (DET)45.
In that case, the x-axis represents the true positive rate.
As \(TPR + FAR = 1\), these curves are equivalent.
Each application has its own requirements. Depending on the related risks, you may need to adjust this threshold. There is a trade-off between comfort (good user always recognized) and security/risks (due to not-enrolled users recognized).
Equal Error Rate EER
As the threshold depends on the application, one way to share the recognition results is the Equal Error Rate, where:
\[EER = FNIR = FPIR\]In other words, the threshold is set in such a way that a false rejection is as likely as false acceptance. This is one way of sharing the results and comparing biometrics accuracy on the same basis.
Security
Introduction to security
In all IT systems, security needs to be carefully considered. A biometric system is more critical than a system with passwords: passwords can be revoked, biometry cannot. Therefore, if someone is able to get your stored biometric template, he might be able to authenticate you forever.
In this part, we will list security issues that are specific to biometric systems. Next, we will describe how templates can be protected, to prevent reuse in case of a breach.
Attacks46, 47, 48
There are several ways to attack a biometric system:
- Intrinsic failure/ Zero-effort attack, which are user trying to get recognized as someone was not enrolled at all. The security here relies on the system performances (FAR/FRR, FNIR/FPIR)
- Spoofing, where a counterfeit is presented to the sensor (a gummy finger, a photo of your iris, a 3D printed face, …). To prevent this attack, the system must check the liveness of the subject.
- Hill-Climbing attack: If the attacker is able to bypass the sensor, he can inject generated data. If the system returns a score, the attacker can try again, see if the newly injected data is better or not, and then optimize his generator. This is a common Machine Learning attack, and the single way to prevent it is to not return a score. Only the final decision needs to be returned to the user.
- Template leakage, where the attacker is able to dump the database of template. With this in his hand, he can take the time to create accurate counterfeit; reuse the template on another system; perform cross analysis between databases…
- Template modification, where the attacker modifies the database, for instance he exchanges records, so
Ais recognized asB, or modifies a few bits in a template. This can be easily prevented using CRC.
The template leakage is one of the most problematic attacks, as it affects many users at a time, and effects outside the system cannot be controlled. Because also legislation like GDPR tries to reduce leaks of personal data.
Template Desirable Properties
To prevent any impact of template leakage, templates should have the two following properties:
Irreversibility: It must not be possible to reconstruct a fake sample from the template. If we look at feature extraction process, the raw image is transformed to get specific discriminative information. Normally, you are unable to go back to the original template, as feature extraction discards irrelevant information. However, the left features are the important one. Even if the reconstructed image is not exactly the same than the raw initial one, as long as they share the same properties, the reconstructed image will have the same feature vector.
Unlinkability: Unlinkability is the impossibility to link two templates from the same user protected differently. Encrypting a template with two different keys is a starting point, but as the template needs to be decrypted before entering the matcher, this is a relatively weak protection. Unlinkability can be enforced if two other properties exist:
- Renewability: The same biometric data can lead to different protected template from the same templates that look different
- Diversity: The difference between two protected templates from the same user should be large enough
Many biometric systems do not have irreversibility nor unlinkability properties enforced.
Here comes template protection schemes: These are mechanisms which prevent the use of a template without a secret knowledge, or the extraction of information from the template. The following part will present the main template protection mechanisms and the main idea behind.
Template Protection Mechanisms
There are three groups of template protection mechanisms:
- Cancelable biometrics/Feature transform: The feature processing is done in such a way it is impossible to go back to the initial data,
- Crypto-systems: The template is used to construct a keyed system,
- Homomorphic encryption: Computations are done on the encrypted domain.
The two first categories have the disadvantages of needing major changes in the biometric system, and system’s accuracy decreases. Homomorphic encryption is not the best option either, because not all algorithms can be executed in the crypto-domain, and it suffers from speed and memory issues.
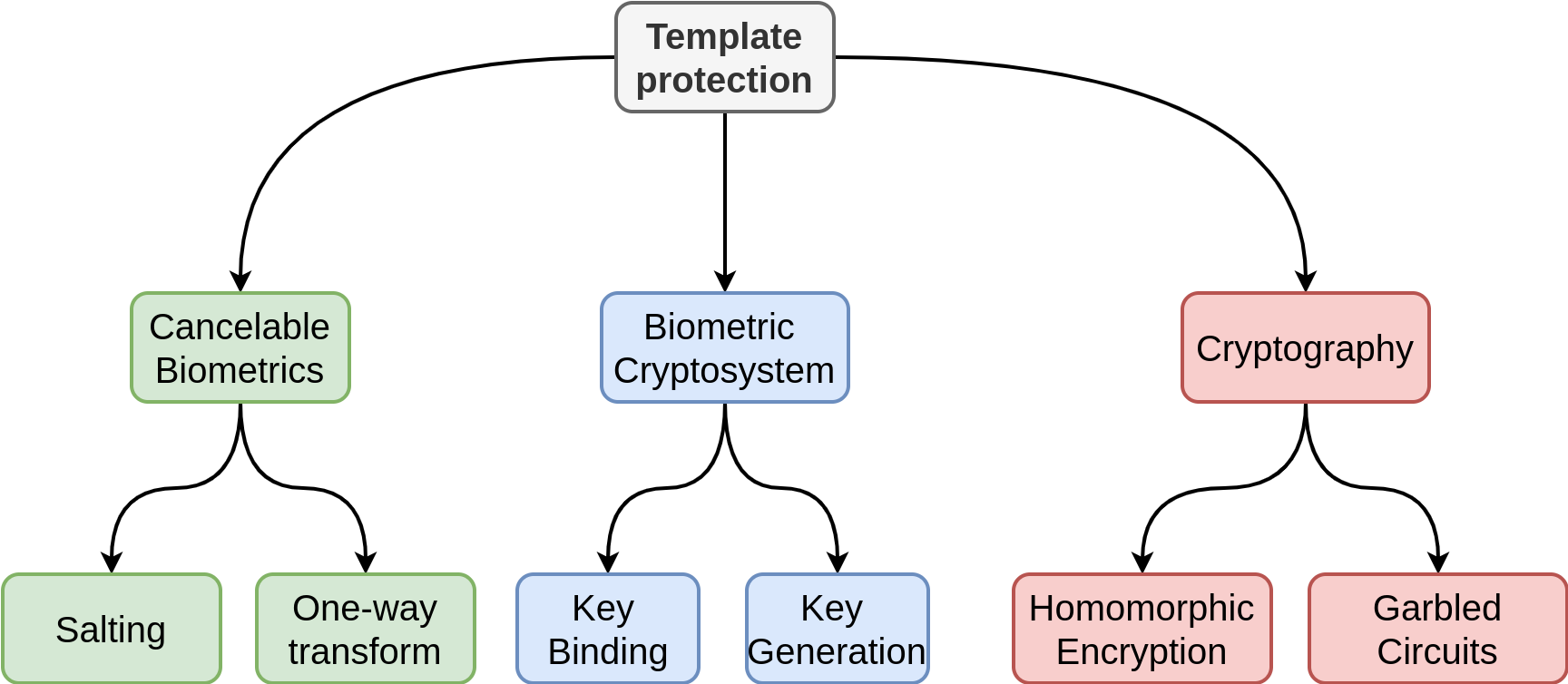
Cancelable Biometrics 49,50
Cancelable biometrics play on the feature processing part. Templates are modified thanks to an additional data, which configures the processing. This information needs to be remembered for each user template.
There are two main categories within this group:
- Non-inversible transform, where a transformation is one in such a way it is impossible to go back to the initial features
- Salting, where additional data is used to make the template irreversible. We must not see salting as in password hashing. Here, the salt is more like a random number used as a configuration seed for the transformation.
Biohashing 51

Biohashing is one of the most well-known cancelable biometric technics.
In the initial paper, they apply the technic to fingerprints, where it follows a three-steps process:
- Capture of the image \(\mathbf{I} \in \mathbb{R}^N\)
- Wavelet transform of the image \(\Gamma \in \mathbb{R}^M\)
- Discretization \(\mathbf{b} \in \{0, 1\}^m\)
The two first steps are “normal” biometric steps: 1) capture of a sample and 2) feature extraction.
The third step is the “core” of biohashing. $m$ random numbers \(\mathbb{r}_i \in \mathbb{R}^M\) are generated. For each of these random, we compute the dot product with \(\Gamma\) as
\[f(\mathbf{r_i}, \Gamma) = \frac{1}{M} \sum_{j=1}^M r_{i, j} \Gamma_j\]And next, given a threshold $\tau$, the value is binarized as:
\[b_i = \left\{ \begin{array}{ll} 0 & \mbox{ if } f(\mathbf{r_i}, \Gamma) \leq \tau \\ 1 & \mbox{otherwise} \end{array} \right.\]The list of random numbers is stored for each user, on the user side or on the server side, depending on the application. It is impossible from the binary vector and the random numbers to find back the initial features, ensuring irreversibility.
To perform a verification, a probe needs to be binarized using the random numbers of the user to verify. Next, the Hamming distance between the binarized template and the binarized probe is computed to decide whether it is the right user or not.
For Identification, the system needs to perform \(n\) different binarization (if there are \(n\) users in the database) and compare the binarized probe to the binarized pattern.
Crypto Systems
Despite the name, crypto-systems do not rely on direct template encryption. Instead, these methods try to use bio-input in such a way they can be used as a key.
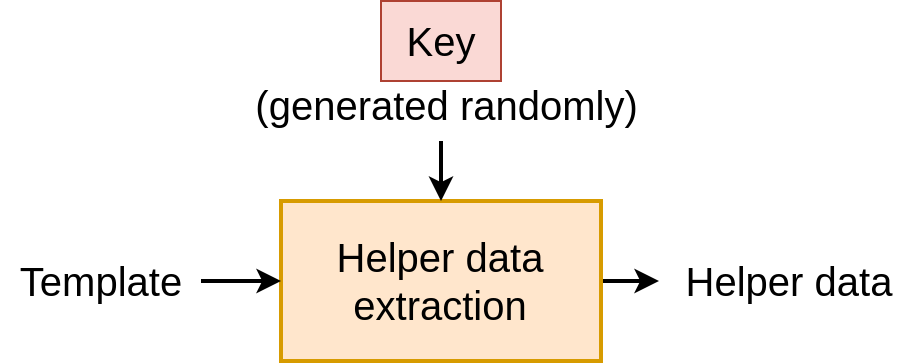
Most of these schemes rely on “helper data”, which are generated at enrollment using the user template. This helper data, combined with a user probe will enable to reconstruct a kind of key, and the system will check if the key is the same as the one of the enrollment or not.
There are two main categories, which differs on where the key comes from:
- key binding: The key is randomly generated by the system, and the helper data is generated thanks to this key and the biometric template.
- key generation: The helper data is derived from the biometric template only. Next, the key is generated using the helper data and the template.
Many of these schemes rely on error correcting code, as a way to recover the initial template from a slightly different one.
Key Binding Scheme52, 53
In key binding scheme, a key is randomly generated during the enrollment (so we are sure that it reflects nothing about the template).
Then, an “helper data” is generated from this key and the template to protect.
The helper data needs to be stored, associated with the key.
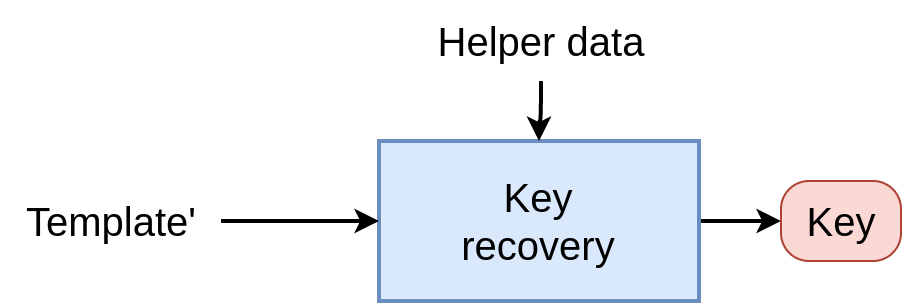
During authentication, the goal is to recover the key given the helper data, and a probe which is supposed close enough from the initial template. The matcher should verify that the key can be reconstructed. Therefore, the key is considered as the “protected template”.
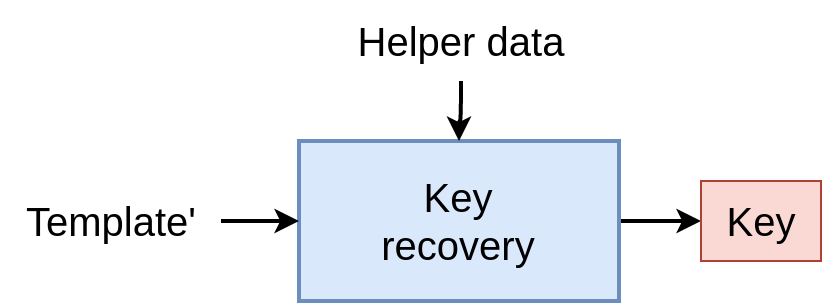
In this group, there are two main schemes:
Key Generation Scheme54, 55
In the key generation scheme, an helper data is derived from the template. Therefore, with exactly the same template, you get exactly the same helper data. Next, a key is generated from the template AND the helper data.
As the template will never be exactly the same on another capture, the helper data should be stored associated with the key.
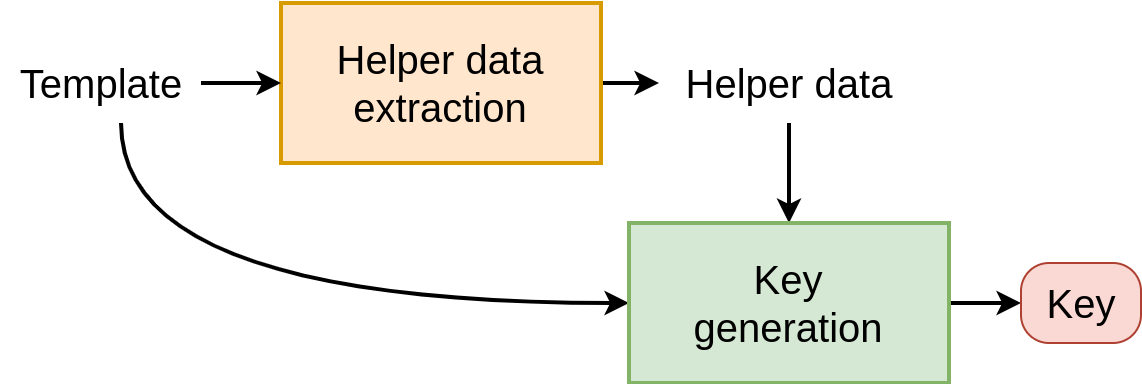
For the authentication phase, the recovery step is similar to the binding one, where the key should be recovered using the probe and the helper data.
Here, the two most known schemes are:
Operation on the Encrypted Domain 56
The last group relies on cryptography.
We can list three technics:
- Homomorphic Encryption
- Functional Encryption
- Garbled circuits
Homormorphic encryption is a particular cryptosystem where operations such as \(+, -, \times\) can be done on the encrypted domain. Therefore, it is possible to compare a template to a probe, without revealing the template at any time. Only the score of the matcher is decrypted.
The main problems with these schemes are:
- Algorithm reworking: There is no \(/\) operator, which restricts the algorithms
- Error-prone The number of total operations is bounded, otherwise overflow errors occurs
- Efficiency: Homormorphic encryption inflates drastically the input, leading to a lot of computation, making these scheme extremely low.
These kinds of cryptographies are still young, and improvement might be done in the future to tackle these different issues.
Conclusion
In this article, we made a large introduction to biometry.
- We introduced biometry by comparing it to the other authentication methods
- We presented the main elements necessary for a biometry infrastructure
- We listed the main biometric technics available
- We presented the evaluation methods
- We highlighted security issues and the way to protect the system.
Sources
-
Alex Weinert, (2019). Your Pa$$word doesn’t matter ↩
-
Kevin Lee, Sten Sjöberg, and Arvind Narayanan. 2022. Password policies of most top websites fail to follow best practices. In Proceedings of the Eighteenth USENIX Conference on Usable Privacy and Security (SOUPS’22). USENIX Association, USA, Article 30, 561–580. ↩
-
Richard Shay, Saranga Komanduri, Patrick Gage Kelley, Pedro Giovanni Leon, Michelle L. Mazurek, Lujo Bauer, Nicolas Christin, and Lorrie Faith Cranor. 2010. Encountering stronger password requirements: user attitudes and behaviors. In Proceedings of the Sixth Symposium on Usable Privacy and Security (SOUPS ‘10). Association for Computing Machinery, New York, NY, USA, Article 2, 1–20. https://doi.org/10.1145/1837110.1837113 ↩
-
Inglesant, Philip & Sasse, Angela. (2010). The true cost of unusable password policies. 1. 383-392. 10.1145/1753326.1753384. ↩
-
Daugman, J. (2004). How iris recognition works. IEEE Trans. Circuits Syst. Video Techn., 14, 21-30. ↩
-
Fukuta, K., Nakagawa, T., Hayashi, Y., Hatanaka, Y., Hara, T. & Fujita, H. (2008). images.Personal Identification Based on Blood Vessels of Retinal Fundus Images In J. M. Reinhardt & J. P. W. Pluim (eds.), Medical Imaging: Image Processing (p./pp. 69141V), : SPIE. ISBN: 9780819470980 ↩ ↩2
-
Qamber, Sana & Waheed, Zahra & Akram, M.. (2012). Personal identification system based on vascular pattern of human retina 2012 Cairo International Biomedical Engineering Conference, CIBEC 2012. 64-67. 10.1109/CIBEC.2012.6473297. ↩
-
Condurache, Alexandru Paul & Kotzerke, J. & Mertins, A.. (2012). Robust retina-based person authentication using the sparse classifier European Signal Processing Conference. 1514-1518. ↩
-
Rahal, S.M. & Aboalsamah, H.A. & Muteb, K.N.. (2006).Multimodal Biometric Authentication System - MBAS. 1. 1026 - 1030. 10.1109/ICTTA.2006.1684515. ↩
-
Maltoni, D. (2003). A Tutorial on Fingerprint Recognition. In M. Tistarelli, J. Bigün & E. Grosso (eds.), Advanced Studies in Biometrics (p./pp. 43-68), : Springer. ISBN: 3-540-26204-0 ↩
-
Sree Rama Murthy kora,Praveen Verma, Yashwant Kashyap: Palmprint Recognition (Slides) ↩
-
Krishneswari, K & Arumugam, S.. (2010). A review on palmprint verification system ↩
-
Jain, Anil & Ross, Arun & Pankanti, S.. (2002). A Prototype Hand Geometry-based Verification System ↩ ↩2
-
L. Yang, G. Yang, Y. Yin and X. Xi, “Finger Vein Recognition With Anatomy Structure Analysis,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 8, pp. 1892-1905, Aug. 2018, doi: 10.1109/TCSVT.2017.2684833. ↩
-
ZKTECO College - Fundamental of Finger Vein Recognition ↩ ↩2
-
Wang, Kejun & Ma, Hui & Popoola, Oluwatoyin & Liu, Jingyu. (2011). Finger Vein Recognition. 10.5772/18025. ↩
-
ion Marques, 2010 Face Recognition Algorithms ↩ ↩2 ↩3
-
Schroff, Florian & Kalenichenko, Dmitry & Philbin, James. (2015). FaceNet: A Unified Embedding for Face Recognition and Clustering.815-823. 10.1109/CVPR.2015.7298682. ↩ ↩2
-
Deng, Jiankang & Guo, Jia & Zafeiriou, Stefanos. (2018). ArcFace: Additive Angular Margin Loss for Deep Face Recognition ↩ ↩2
-
Taigman, Yaniv & Yang, Ming & Ranzato, Marc’Aurelio & Wolf, Lior. (2014). DeepFace: Closing the Gap to Human-Level Performance in Face Verification. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 10.1109/CVPR.2014.220. ↩ ↩2
-
Brunelli, Roberto & Poggio, Tomaso. (1992). Face Recognition through Geometrical Features.. Lecture Notes in Computer Science. 588. 792-800. ↩
-
Shi, J., Samal, A., & Marx, D. (2006). How effective are landmarks and their geometry for face recognition? Computer Vision and Image Understanding, 102(2), 117–133. ↩ ↩2
-
Ghimire, Deepak & Lee, Joonwhoan. (2013). Geometric Feature-Based Facial Expression Recognition in Image Sequences Using Multi-Class AdaBoost and Support Vector Machines. Sensors. 13. 7714-7734. 10.3390/s130607714. ↩
-
Amnon Shashua, (1992). Geometry and Photometry in 3D Visual Recognition # Alignement of faces ↩
-
Ana M. Guzman Tamayo, (2011), Thermal Imaging As A Biometrics Approach To Facial Signature Authentication ↩ ↩2 ↩3
-
Christensen, Justin & Vaeth, M & Wenzel, A. (2012). Thermographic imaging of facial skin—gender differences and temperature changes over time in healthy subjects. Dento maxillo facial radiology. 41. 10.1259/dmfr/55922484. ↩
-
Chung, Joon Son & Nagrani, Arsha & Zisserman, Andrew. (2018). VoxCeleb2: Deep Speaker Recognition. 1086-1090. 10.21437/Interspeech.2018-1929. ↩ ↩2
-
Muda, Lindasalwa & Begam, Mumtaj & Elamvazuthi, Irraivan. (2010).Voice Recognition Algorithms using Mel Frequency Cepstral Coefficient (MFCC) and Dynamic Time Warping (DTW) Techniques . J Comput. 2. ↩ ↩2
-
Markowitz, Judith. (2000). Voice Biometrics, Communications of the ACM. 43. 10.1145/348941.348995. ↩
-
Reynolds, D.A., Quatieri, T.F., & Dunn, R.B. (2000). Speaker Verification Using Adapted Gaussian Mixture Models. Digit. Signal Process., 10, 19-41. ↩ ↩2
-
L.R, Sudha & R., Bhavani. (2011). Biometric Authorization System Using Gait Biometry.International Journal of Computer Science, Engineering and Applications. 1. 10.5121/ijcsea.2011.1401. ↩ ↩2
-
Baek, Duin & Musale, Pratik. (2019). You Walk, We Authenticate: Lightweight Seamless Authentication Based on Gait in Wearable IoT Systems IEEE Access. 7. 37883 - 37895. 10.1109/ACCESS.2019.2906663. ↩ ↩2
-
Muaaz, M., & Mayrhofer, R. (2017). Smartphone-Based Gait Recognition: From Authentication to Imitation. IEEE Transactions on Mobile Computing, 16(11), 3209–3221. doi:10.1109/tmc.2017.2686855 ↩ ↩2
-
Hoang T, Choi D. Secure and Privacy Enhanced Gait Authentication on Smart Phone ScientificWorldJournal. 2014;2014:438254. doi: 10.1155/2014/438254. Epub 2014 May 14. PMID: 24955403; PMCID: PMC4052054. ↩ ↩2 ↩3
-
Muhammad Muaaz and René Mayrhofer. 2014. Orientation Independent Cell Phone Based Gait Authentication In Proceedings of the 12th International Conference on Advances in Mobile Computing and Multimedia (MoMM ‘14). Association for Computing Machinery, New York, NY, USA, 161–164. ↩
-
Leggett, J. J., Williams, G., Usnick, M. & Longnecker, M. (1991). Dynamic Identity Verification via Keystroke Characteristics.. Int. J. Man Mach. Stud., 35, 859-870. ↩
-
S. J. Alghamdi and L. A. Elrefaei, “Dynamic User Verification Using Touch Keystroke Based on Medians Vector Proximity,” 2015 7th International Conference on Computational Intelligence, Communication Systems and Networks, Riga, Latvia, 2015, pp. 121-126, doi: 10.1109/CICSyN.2015.31. ↩
-
Md Liakat Ali, John V. Monaco, Charles C. Tappert, and Meikang Qiu. 2017. Keystroke Biometric Systems for User Authentication. Link, J. Signal Process. Syst. 86, 2–3 (March 2017), 175–190. https://doi.org/10.1007/s11265-016-1114-9 ↩
-
Wirotius, M. & Ramel, Jean-Yves & Vincent, Nicole. (2004). Selection of Points for On-Line Signature Comparison/ 503- 508. 10.1109/IWFHR.2004.92. ↩ ↩2
-
Fierrez-Aguilar, J., Nanni, L., Lopez-Peñalba, J., Ortega-Garcia, J., & Maltoni, D. (2005). An On-Line Signature Verification System Based on Fusion of Local and Global Information. Audio and Video-Based Biometric Person Authentication, 523–532. doi:10.1007/11527923_54 ↩ ↩2
-
Galbally, Javier & Diaz, Moises & Ferrer, Miguel & Gomez-Barrero, Marta & Morales, Aythami & Fierrez, Julian. (2015). On-Line Signature Recognition through the Combination of Real Dynamic Data and Synthetically Generated Static Data Pattern Recognition. 48. 2921–2934. 10.1016/j.patcog.2015.03.019. ↩ ↩2 ↩3
-
Detection error tradeoff (DET) curve, scikit-learn library documentation ↩
-
Jain, Anil & Nandakumar, Karthik & Nagar, Abhishek. (2008). Biometric Template Security, 2008. EURASIP Journal on Advances in Signal Processing. 2008. 10.1155/2008/579416. ↩
-
Choudhury, Bismita & Then, Patrick & Issac, Biju & Raman, Valliappan & Haldar, Manas. (2018). A Survey on Biometrics and Cancelable Biometrics Systems. International Journal of Image and Graphics. 18. 1850006. 10.1142/S0219467818500067. ↩
-
Ratha, Nalini & Connell, Jonathan & Bolle, Ruud. (2001). Enhancing Security and Privacy in Biometrics-Based Authentication Systems. IBM Systems Journal. 40. 614-634. 10.1147/sj.403.0614. ↩
-
Stokkenes, M., Ramachandra, R., Raja, K. B., Sigaard, M., Gomez-Barrero, M., & Busch, C. (2017). Multi-biometric Template Protection on Smartphones: An Approach Based on Binarized Statistical Features and Bloom Filters. Lecture Notes in Computer Science, 385–392. ↩
-
Choudhury, Bismita & Then, Patrick & Issac, Biju & Raman, Valliappan & Haldar, Manas. (2018). A Survey on Biometrics and Cancelable Biometrics Systems. International Journal of Image and Graphics. 18. 1850006. 10.1142/S0219467818500067. ↩
-
Jin, A. T. B., Ling, D. N. C., & Goh, A. (2004). Biohashing: two factor authentication featuring fingerprint data and tokenized random number. Pattern Recognition, 37(11), 2245–2255. ↩
-
Juels, Ari. (2002). A Fuzzy Vault Scheme. ↩ ↩2
-
Juels, Ari & Wattenberg, Martin. (1999). A Fuzzy Commitment Scheme. Proceedings of the ACM Conference on Computer and Communications Security. 1. 10.1145/319709.319714. ↩ ↩2
-
Li, Qiming & Sutcu, Yagiz & Memon, Nasir. (2006). Secure Sketch for Biometric Templates., Adv. Cryptology Asiacrypt. 4284. 99-113. 10.1007/11935230_7. ↩ ↩2
-
Dodis, Yevgeniy & Reyzin, Leonid & Smith, Adam. (2004). Fuzzy Extractors: How to Generate Strong Keys from Biometrics and Other Noisy Data. Computing Research Repository - CORR. 38. 523-540. 10.1137/060651380. ↩ ↩2
-
Gomez-Barrero, M., Maiorana, E., Galbally, J., Campisi, P., & Fierrez, J. (2017). Multi-biometric template protection based on Homomorphic Encryption. Pattern Recognition, 67, 149–163. ↩
>> You can subscribe to my mailing list here for a monthly update. <<